Chapter 11 Weighting
Strictly speaking, weighting comes before aggregation. However, in order to understand the effects of weights, we need to aggregate the index first.
Weighting in composite indicators is a thorny issue, which attracts considerable attention and is often one of the main focuses of critics. Weighting openly expresses a subjective opinion on the relative importance of each indicator relative to the others, and this opinion can easily be contested.
While this criticism definitely has some basis, weights can be viewed as a type of model parameter, and any model (e.g. engineering models, climate models, economic models) is full of uncertain parameters. In large models, these parameters are less evident since they are inside rather complex model code. Weights in composite indicators are easy to criticise since the model of a composite indicator is quite simple, usually using simple averages of indicator values.
That said, weights do need to be carefully considered, taking into account at least:
- The relative conceptual importance of indicators: is indicator A more, less, or equally important to indicator B?
- The statistical implications of the weights
- How to communicate the weights to end users
The last point is important if the index is for advocacy/awareness. Weights may be fine tuned to account for statistical considerations, but the result may make little sense to the public or the media.
Overall, weighting is a large topic which cannot be covered in detail here. Nevertheless, this chapter gives some introduction and points to further references.
11.1 Approaches to weighting
Broadly, weighting approaches can be divided into those that are based on expert judgment, and those that are based on statistical considerations. Then there are approaches that combine the two.
11.1.1 Equal weighting
The most common approach to weighting is simply to make all weights equal to one another. This may seem like an unjustifiable simplification, but in practice, experts often give near-equal weights when asked, and statistical approaches may give weights that are so unequal that it may be hard to justify them to stakeholders. This is why many composite indicators use equal weights. A further consideration is that the results of a composite indicator are often less sensitive to their weights than you might think.
That said, a number of other methods exist, some of which are discussed in the following sections.
11.1.2 Budget allocation
Fundamentally, composite indicators involve breaking down a complex multidimensional concept into sub-concepts, and possibly breaking those sub-concepts down into sub-sub-concepts, and so on. Generally, you keep doing this until you arrive at the point where the (sub-)^n-concepts are sufficiently specific that they can be directly measured with a small group of indicators.
Regardless of the aggregation level that you are at, however, some of the indicators (or aggregates) in the group are likely to be more or less important to the concept you are trying to measure than others.
Take the example of university rankings. One might consider the following indicators to be relevant to the notion of “excellence” for a university:
- Number of publications in top-tier journals (research output)
- Teaching reputation, e.g. through a survey (teaching quality)
- Research funding from private companies (industry links)
- Percentage of international students (global renown)
- Mean earning of graduates (future prospects of students)
These may all be relevant for the concept, but the relative importance is definitely debatable. For example, if you are a prospective student, you might prioritise the teaching quality and graduate earnings. If you are researcher, you might priorities publications and research funding. And so on. The two points to make here are:
- Indicators are often not equally important to the concept, and
- Different people have different opinions on what should be more or less important.
Bringing this back to the issue of weights, it is important to make sure that the relative contributions of the indicators to the index scorers reflect the intended importance. This can be achieved by changing the weights attached to each indicator, and the weights of higher aggregation levels.
How then do we understand which indicators should be the most important to the concept? One way is to simply use our own opinion. But this does not reflect a diversity of viewpoints.
The budget allocation method is a simple way of eliciting weights from a group of experts. The idea is to get a group of experts on the concept, stakeholders and end-users, ideally from different backgrounds. Then each member of the group is given 100 “coins” which they can “spend” on the indicators. Members allocate their budget to each indicator, so that they give more of the budget to important indicators, and less to less important ones.
This is a simple way of distributing weight to indicators, in a way that is easy for people to understand and to give their opinions. You can take the results, and take the average weight for each indicator. You can even infer a weight-distribution over each indicator which could feed into an uncertainty analysis.
11.1.3 Principle component analysis
A very different approach is to use principle component analysis (PCA). PCA is a statistical approach, which rotates your indicator data into a new set of coordinates with special properties.
One way of looking at indicator data is as data points in a multidimensional space. If we only have two indicators, then any unit can be plotted as a point on a two-dimensional plot, where the x-axis is the first indicator, and the y-axis is the second.
Ind1 <- 35
Ind2 <- 60
plot(Ind1, Ind2, main = "World's most boring plot")
Each point on this beautiful base-R plot represents a unit (here we only have one).
If we have three indicators, then we will have three axes (i.e. a 3D plot). If we have more than three, then the point lives in a hyperspace which we can’t really visualise.
Anyway, the main point here is that indicator data can be plotted as points in a space, where each axis (dimension) is an indicator.
What PCA does, is that it rotates the data so that the axes are no longer indicators, but instead are linear combinations of indicators. And this is done so that the first axis is the linear combination of indicators that explains the most variance. If this is not making much sense (and if this is the first time you have encountered PCA then it probably won’t), I would recommend to look at one of the many visualisations of PCA on the internet, e.g. this one.
PCA is useful for composite indicators, because if you use an arithmetic mean, then you are using a linear combination of indicators. And the first principle component gives the weights that maximise the variance of the units. In other words, if you use PCA weights, you will have the best weights for discriminating between units, and for capturing as much information from the underlying indicators.
This sounds perfect, but the downside is that PCA weights do not care about the relative importance of indicators. Typically, PCA assigns the highest weights to indicators with the highest correlations with other indicators, and this can result in a very unbalanced combination of indicators. Still, PCA has a number of nice properties, and has the advantage of being a purely statistical approach.
11.1.4 Weight optimisation
If you choose to go for the budget allocation approach, to match weights to the opinions of experts, or indeed your own opinion, there is a catch that is not very obvious. Put simply, weights do not directly translate into importance.
To understand why, we must first define what “importance” means. Actually there is more than one way to look at this, but one possible measure is to use the (nonlinear) correlation between each indicator and the overall index. If the correlation is high, the indicator is well-reflected in the index scores, and vice versa.
If we accept this definition of importance, then it’s important to realise that this correlation is affected not only by the weights attached to each indicator, but also by the correlations between indicators. This means that these correlations must be accounted for in choosing weights that agree with the budgets assigned by the group of experts.
In fact, it is possible to reverse-engineer the weights either analytically using a linear solution or numerically using a nonlinear solution. While the former method is far quicker than a nonlinear optimisation, it is only applicable in the case of a single level of aggregation, with an arithmetic mean, and using linear correlation as a measure. Therefore in COINr, the second method is used.
11.2 Weighting tools in COINr
As seen in the chapter on Aggregation, weights are used to calculate the aggregated data set, and are one of the inputs to the aggregate() function. These can either be directly specified as a list, or as a character string which points to one of the sets of weights stored under .$Parameters$Weights. There is no limit to the number of sets of weights that can be stored here. So how do we create new sets of weights?
11.2.1 Manual weighting
The simplest approach is to make manual adjustments. First, make a copy of the existing weights.
library(COINr6)
# quietly build data set
ASEM <- build_ASEM()
NewWeights <- ASEM$Parameters$Weights$Original
head(NewWeights)
## AgLevel Code Weight
## 1 1 Goods 1
## 2 1 Services 1
## 3 1 FDI 1
## 4 1 PRemit 1
## 5 1 ForPort 1
## 6 1 CostImpEx 1The structure of the weights is a data frame, with each row being either an indicator or aggregation. The AgLevel column points to the aggregation level, and the Weight column is the weight, which is relative inside its aggregation group.
This last point is important so let’s clarify. When aggregating, the weights within each group are normalised to sum to one. So if we have three indicators in a group, and we specify the weights as all ones, the actual weights will each be 1/3. This means that actually, we can put any number we like if we are aiming for equal weighting, as long as it is the same for each indicator.
Another implication of relative weighting is that the number of indicators within a group also matters. If we have two indicators in a group, equally weighted, their weight is 0.5. If we have ten, they are each weighted 0.1. Moreover, an indicator’s final weight in the index is also affected by its parent group weights (e.. sub-pillar, pillar weights). This is why it is important to be aware of the so-called “effective weights” which are the final weights of the indicators (and each aggregate in the index). COINr has a function to calculate this: see Effective weights.
Anyway, to change the weights we can just directly modify the data frame. Let’s say we want to set the weight of the connectivity sub-index to 0.5.
NewWeights$Weight[NewWeights$Code == "Conn"] <- 0.5
tail(NewWeights)
## AgLevel Code Weight
## 55 2 Environ 1.0
## 56 2 Social 1.0
## 57 2 SusEcFin 1.0
## 58 3 Conn 0.5
## 59 3 Sust 1.0
## 60 4 Index 1.0Now, to actually use these weights in the aggregation, we can either (a) input them directly in the aggregate() function, or first attach them to the COIN and the call aggregate(), pointing to the new set of weights. The latter option seems more sensible because that way, all our sets of weights are neatly stored. Also, we can access this in the reweighting app as explained in the next section. Sets of weights need to be stored as a named data frame in .$Parameters$Weights to be accessible to aggregate().
# put new weights in the COIN
ASEM$Parameters$Weights$NewWeights <- NewWeights
# Aggregate again to get new results
ASEM <- aggregate(ASEM, dset = "Normalised", agweights = "NewWeights")Now the ASEM COIN contains the updated results using the new weights.
11.2.2 Interactive re-weighting with ReW8R
Re-weighting manually, as we have just seen, is quite simple. However, depending on your objectives, weighting can be an iterative process along the lines of:
- Try a set of weights
- Examine correlations
- Check results, rankings
- Adjust weights
- Return to 1.
Doing this at the command line can be time consuming, so COINr includes a “re-weighting app” called rew8r() which lets you interactively adjust weights and explore the effects of doing so.
To run rew8r() you must have already aggregated your data using aggregate(). This is because every time weights are adjusted, rew8r() re-aggregates to find new results, and it needs to know which aggregation method you are using. So, with your pre-aggregated COIN at hand, simply run:
ASEM <- rew8r(ASEM)At this point, a window/tab should open in your browser with the rew8r() app, which looks something like this:
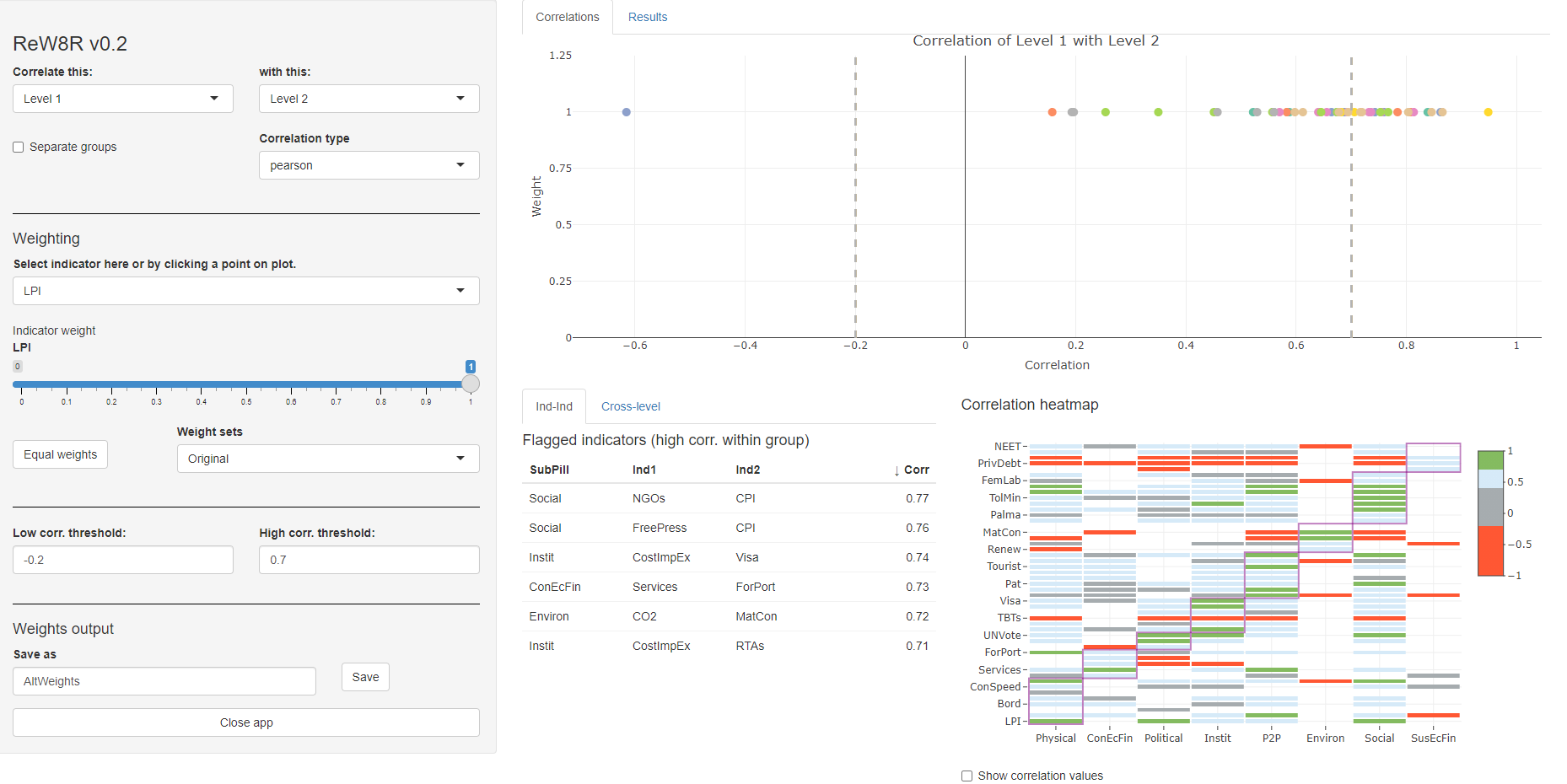
Figure 11.1: rew8r() screenshot
This may look a little over-complicated to begin with, but let’s go through it step by step.
11.2.2.1 Correlations
First of all, rew8r() is based around correlations. Why are correlations important? Because they give an idea of how each indicator is represented in the final index, and at other aggregation levels (see earlier discussion in this chapter).
The rew8r() app allows you to check the correlations of anything against anything else. The two dropdown menus in the top left allow you to select which aggregation level to correlate against which other. In the screenshot above, the indicators (Level 1) are being correlated against the pillars (Level 2), but this can be changed to any of the levels in the index (the first level should always be below the second level otherwise it can cause errors). You can also select which type of correlation to examine, either Pearson (i.e. “standard” correlation), Spearman rank correlation, or Kendall’s tau (an alternative rank correlation).
The correlations themselves are shown in two plots - the first is the scatter plot in the upper right part of the window, which plots the correlation of each indicator in Level 1 on the horizontal axis with its parent in Level 2, against its weight (in Level 1) on the vertical axis. We will come back to this shortly.
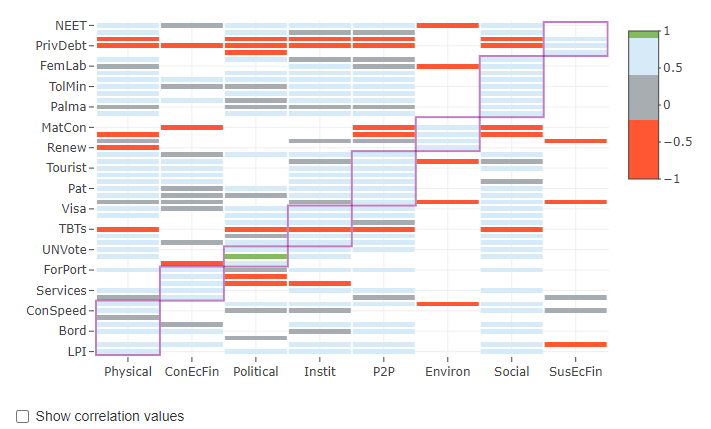
Figure 11.2: Heatmap screenshot (in rew8r)
The second plot is a heatmap of the correlation matrix (between Level 1 and Level 2 in this case) which is shown in the lower right corner. This gives the correlation values between all the indicators/groups of each level as colours according to a discrete colour map. This colour map intends to highlight highly correlated indicators (green), as well as negative or low-correlated indicators (red). These thresholds can be adjusted by adjusting the low and high correlation threshold dropdown menus in the side panel (on the left). The aggregation groups are also shown as overlaid rectangles, and correlation values can be turned on and off using the checkbox below the heatmap. The point of this plot is to show at a glance, where there are very high or low correlations, possibly within aggregation groups. For example, indicators that are negatively correlated with their aggregation group can be problematic. Note that correlation heatmaps can also be generated independently of the app using the plotCorr() function - this is described more in the Multivariate analysis section.
Highly-correlated indicators are also listed in a table at the lower middle of the window. The “Ind-Ind” tab flags any indicators that are above the high correlation threshold, and within the same aggregation group (the aggregation level immediately above the indicator level). Note that this is not dependent on the weights since it regards correlations between indicators only. The “Cross-level” tab instead gives a table which flags any correlations across the two levels selected in side panel, which are above the threshold.
11.2.2.2 Weighting
Let us now turn back to the scatter plot. The scatter plot shows the correlation values on the horizontal axis, but also shows the weight of each indicator or aggregate in the first level selected in the dropdown menu. The purpose here is to show at a glance the weighting, and to make adjustments. To adjust a weight, either click on one of the points in the plot (hovering will show the names of the indicators or aggregates), or select the indicator/aggregate in the dropdown menu in the side panel under the “Weighting” subsection. Then adjust the weight using the slider. Doing this will automatically update all of the plots and tables, so you can see interactively how the correlations change as a result.
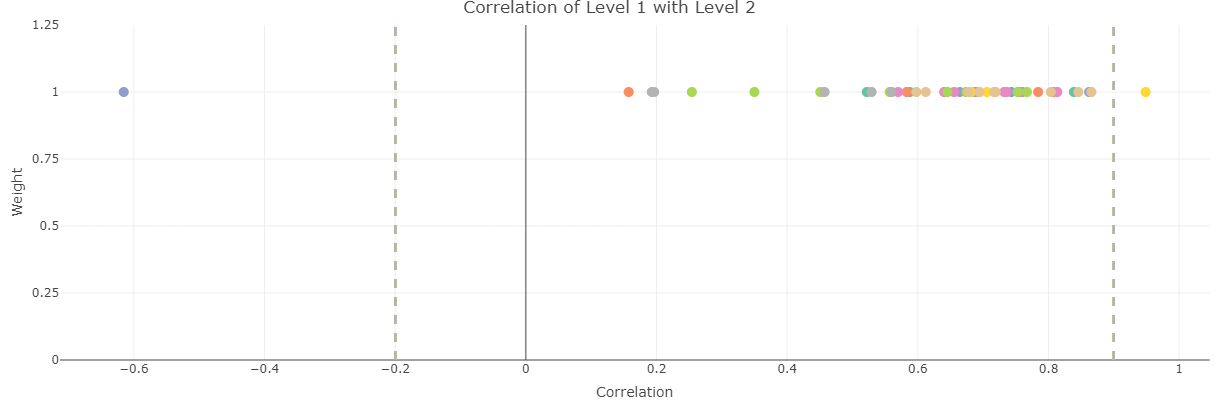
Figure 11.3: Correlation scatter plot screenshots in rew8r().
Figure 11.4: Correlation scatter plot screenshots in rew8r().
Importantly, the scatter plot only shows correlations between each indicator/aggregate in the first level with its parent in the second selected level. When everything is plotted on one plot, this may not be so clear, so the “Separate groups” checkbox in the side panel changes the plot to multiple sub-plots, one for each group in the second selected level. This helps to show how correlations are distributed within each group.
The results of the index, in terms of ranks and scores of units, can be found by switching to the “Results” tab in the main window.
Other than adjusting individual weights, any set of weights that is stored in .$Parameters$Weights can be selected, and this will automatically show the correlations. The button “Equal weights” sets weights to be equal at the current level.
Finally, if you have adjusted the weights and you wish to save the new set of weights back to the COIN, you can do this in the “Weights output” subsection of the side panel. The current set of weights is saved by entering a name and clicking the “Save” button. This saves the set of weights to a list, and when the app is closed (using the “Close app” button), it will return them to the updated COIN under .$Parameters$Weights, with the specified name. You can save multiple sets of weights in the same session, by making adjustments, and assigning a name, and clicking “Save”. When you close the app, all the weight sets will be attached to the COIN. If you don’t click “Close app”, any new weight sets created in the session will be lost.
11.2.3 Automatic re-weighting
As discussed earlier, weighting can also be performed statistically, by optimising or targeting some statistical criteria of interest. COINr includes a few possibilities in this respect.
11.2.3.1 With PCA
The getPCA() function is used as a quick way to perform PCA on COINs. This does two things: first, to output PCA results for any aggregation level; and second, to provide PCA weights corresponding to the “loadings” of the first principle component. As discussed above, this is the linear combination that results in the most explained variance.
The other outputs of getPCA() are left to the Multivariate analysis section. Here, we will focus on weighting. To obtain PCA weights, simply run something like:
ASEM <- getPCA(ASEM, dset = "Aggregated", aglev = 2)This calls the aggregated data set, and performs PCA on aggregation level 2, i.e. the pillars in the case of ASEM. The result is an updated COIN, with a new set of weights called .Parameters$Weights$PCA_AggregatedL2. This is automatically named according to the data set used and the aggregation level.
An important point here is that this weighting represents optimal properties if the components (pillars here) are aggregated directly into a single value. In this example, it is not strictly correct because above the pillar level we have another aggregation (sub-index) before reaching the final index. This means that these weights wouldn’t be strictly correct, because they don’t account for the intermediate level. However, depending on the aggregation structure and weighting (i.e. if it is fairly even) it may give a fairly good approximation.
Note: PCA weights have not been fully tested at the time of writing, treat with a healthy dose of skepticism.
11.2.3.2 Weight optimisation
An alternative approach is to optimise weight iteratively. This is in a way less elegant (and slower) because it uses numerical optimisation, but allows much more flexibility.
The weightOpt() function gives several options in this respect. In short, it allows weights to be optimised to agree with either (a) some pre-specified “importances” (perhaps obtained by the budget allocation method, or perhaps simply equal importance), or (b) to maximise the information conveyed by the composite indicator. Starting with the first option, this is how it can be applied to our example data:
ASEM <- weightOpt(ASEM, itarg = "equal", aglev = 3, out2 = "COIN")
## iterating... squared difference = 0.000814548399872482
## iterating... squared difference = 0.00116234608542398
## iterating... squared difference = 0.00052279688155717
## iterating... squared difference = 0.000271428850497901
## iterating... squared difference = 4.19003122660241e-05
## iterating... squared difference = 1.66726715407502e-06
## iterating... squared difference = 0.000166401854209433
## iterating... squared difference = 0.000357199714112592
## iterating... squared difference = 4.91262049731255e-05
## iterating... squared difference = 0.000189074238231704
## iterating... squared difference = 2.15217457991648e-06
## iterating... squared difference = 4.02429806062667e-05
## iterating... squared difference = 1.04404840785835e-05
## iterating... squared difference = 1.00833908145386e-05
## iterating... squared difference = 2.40420217478906e-06
## Optimisation successful!This targets the aggregation level 3 (sub-index), and the itarg argument here is set to “equal”, which means that the objective is to make the correlations between each sub-index and the index equal to one another. More details of the results of this optimisation are found in the .$Analysis$Weights folder of the object. In particular, we can see the final correlations and the optimised weights:
ASEM$Analysis$Weights$OptimsedLev3$CorrResults
## Desired Obtained OptWeight
## 1 0.5 0.8971336 0.400
## 2 0.5 0.8925119 0.625In this case, the weights are slightly uneven but seem reasonable. The correlations are also almost exactly equal. The full set of weights is found as a new weight set under .$Parameters$Weights.
Other possibilities with the weightOpt() function include:
- Specifying an unequal vector of target importances using the
itargargument. E.g. taking the sub-pillar level, specifyingitarg = c(0.5, 1)would optimise the weights so that the first sub-pillar has half the correlation of the second sub-pillar with the index. - Optimising the weights at other aggregation levels using the
aglevargument - Optimising over other correlation types, e.g. rank correlations, using the
cortypeargument - Aiming to maximise overall correlations by setting
optype = infomax
It’s important to point out that only one level can be optimised at a time, and the optimisation is “conditional” on the weights at other levels. For example, optmising at the sub-index level produces optimal correlations for the sub-indexes, but not for any other level. If we then optimise at lower levels, this will change the correlations of the sub-indexes! So probably the most sensible strategy is to optimise for the last aggregation level (before the index).
That said, an advantage of weightOpt() is that since it is numerical, it can be used for any type of aggregation method, any correlation type, and with any index structure. It calls the aggregation method that you last used to aggregate the index, so it rebuilds the index according to your specifications.
Other correlation types may be of interest when linear correlation (i.e. Pearson correlation) is not a sufficient measure. This is the case for example, when distributions are highly skewed. Rank correlations are robust to outliers and can handle some nonlinearity (but not non-monotonicity). Fully nonlinear correlation methods also exist but most of the time, relationships between indicators are fairly linear. Nonlinear correlation may be included in a future version of COINr.
Setting optype = infomax changes the optimisation criterion, to instead maximise the sum of the correlations, which is equivalent to maximising the information transferred to the index, and is similar to PCA. Like PCA, this can however result in fairly unequal weights, and not infrequently in negative weights.
The weightOpt() function uses a numerical optimisation algorithm which does not always succeed in finding a good solution. Optimisation is a large field in its own right, and is more difficult the more variables you optimise over. If weightOpt() fails to find a good solution, try:
- Decreasing the
tolerargument - this decreases the acceptable error between the target importance and the importance with the final set of weights. - Increasing the
maxiterargument - this is the number of iterations allowed to find a solution within the specified tolerance. By default it is set at 500.
Even then, the algorithm may not always converge, depending on the problem.
11.3 Effective weights
By now, it should be clear that the weight of an indicator is not only affected by its own weight, but also the weights of any aggregate groups to which it belongs. If the aggregation method is the arithmetic mean, the “effective weight”, i.e. the final weight of each indicator, including its parent weights, can be be easily obtained by COINr’s effectiveWeight() function:
# get effective weight info
EffWeights <- effectiveWeight(ASEM)
EffWeights$EffectiveWeightsList
## AgLevel Code EffectiveWeight
## 1 1 Goods 0.02000000
## 2 1 Services 0.02000000
## 3 1 FDI 0.02000000
## 4 1 PRemit 0.02000000
## 5 1 ForPort 0.02000000
## 6 1 CostImpEx 0.01666667
## 7 1 Tariff 0.01666667
## 8 1 TBTs 0.01666667
## 9 1 TIRcon 0.01666667
## 10 1 RTAs 0.01666667
## 11 1 Visa 0.01666667
## 12 1 StMob 0.01250000
## 13 1 Research 0.01250000
## 14 1 Pat 0.01250000
## 15 1 CultServ 0.01250000
## 16 1 CultGood 0.01250000
## 17 1 Tourist 0.01250000
## 18 1 MigStock 0.01250000
## 19 1 Lang 0.01250000
## 20 1 LPI 0.01250000
## 21 1 Flights 0.01250000
## 22 1 Ship 0.01250000
## 23 1 Bord 0.01250000
## 24 1 Elec 0.01250000
## 25 1 Gas 0.01250000
## 26 1 ConSpeed 0.01250000
## 27 1 Cov4G 0.01250000
## 28 1 Embs 0.03333333
## 29 1 IGOs 0.03333333
## 30 1 UNVote 0.03333333
## 31 1 Renew 0.03333333
## 32 1 PrimEner 0.03333333
## 33 1 CO2 0.03333333
## 34 1 MatCon 0.03333333
## 35 1 Forest 0.03333333
## 36 1 Poverty 0.01851852
## 37 1 Palma 0.01851852
## 38 1 TertGrad 0.01851852
## 39 1 FreePress 0.01851852
## 40 1 TolMin 0.01851852
## 41 1 NGOs 0.01851852
## 42 1 CPI 0.01851852
## 43 1 FemLab 0.01851852
## 44 1 WomParl 0.01851852
## 45 1 PubDebt 0.03333333
## 46 1 PrivDebt 0.03333333
## 47 1 GDPGrow 0.03333333
## 48 1 RDExp 0.03333333
## 49 1 NEET 0.03333333
## 50 2 Physical 0.10000000
## 51 2 ConEcFin 0.10000000
## 52 2 Political 0.10000000
## 53 2 Instit 0.10000000
## 54 2 P2P 0.10000000
## 55 2 Environ 0.16666667
## 56 2 Social 0.16666667
## 57 2 SusEcFin 0.16666667
## 58 3 Conn 0.50000000
## 59 3 Sust 0.50000000
## 60 4 Index 1.00000000A nice way to visualise this is to call plotframework() (see Initial visualisation and analysis). effectiveWeight() also gives other info on the parents of each indicator/aggregate which may be useful for some purposes (e.g. some types of plots external to COINr).
11.4 Final points
Weighting and correlations is a complex topic, which is important to explore and address. On the other hand, weighting and correlations are just one part of a composite indicator, and balancing and optimising weights probably not be pursued at the expense of building a confusing composite indicator that makes no sense to most people (depending on the context and application).